The web as we know it is changing. Be these changes small or large we have already gone way beyond a mere collection of pages linked together and are now at the stage of connecting individuals through social interaction and harnessing their collective intelligence. The next step appears to be evolving towards the concept of the semantic web through the use of feeds and markup technologies (RDF, OWL, XML, Microformats etc.) to represent meanings in information which allow us to infer and connect knowledge within and around it.
A lot of this will involve annotating information to make it machine understandable (and not just readable); we will design for re-use of information. The upshot of all this should mean that the user spends less time and effort carrying out complex tasks.
Put another way (from Wikipedia):
“The Semantic Web is an evolving extension of the World Wide Web in which web content can be expressed not only in natural language, but also in a format that can be read and used by automated tools, thus permitting people and machines to find, share and integrate information more easily.”
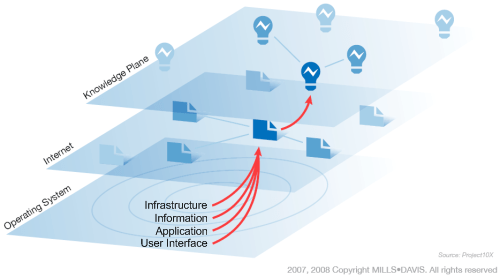
A roadmap might look something like this and interestingly almost exactly mirrors how information architects commonly define the process of converting Data to Information to Knowledge to Wisdom (or intelligence) in the human mind:
- Stage 1 [DATA] – connecting information (the humble hyperlink)
- Data on its own tells us very little
- By observing context, we can distinguish data from information
- Stage 2 [INFO] – connecting people (social networking)
- Information is derived as we organise and present data in various ways
- Organisation can change meaning (either intentionally or unintentionally)
- Presentation enhances existing meaning, mostly on a sensory level
- Stage 3 [KNOWLEDGE] – connecting knowledge (semantic web)
- Knowledge can be distinguished from information by the complexity of the experience used to communicate it
- Design helps the user create knowledge from information by experiencing the it in various ways
- Conversations and stories are the traditional delivery mechanisms for knowledge
- Stage 4 [WISDOM] – connecting intelligence (ubiquitous web)
- Wisdom is the understanding of enough patterns to use knowledge in new ways and situations
- It is personal, hard to share and reflective
Getting there will take some time to develop but already we are seeing major sites like Amazon and Flickr exposing their data via REST APIs allowing for it to be reused and remixed. What we are beginning to see is websites as web services; the unstructured is becoming structured (more detail here). What you end up with is the web as one big re-mixable database platform upon which new applications will be built to manipulate data in ways unthought of before. (Potential applications)
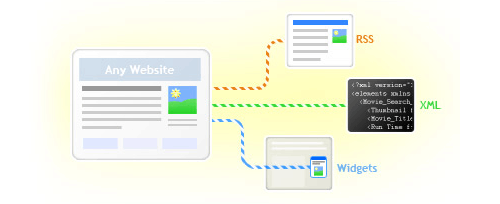
Helping this along the way are a number of freely available tools which make it easier to do things that only programmers could do before by allowing anyone to scrape content from web pages or feeds and then manipulate them however they like (legal issues aside). Here are the main contenders which I have found particularly useful:

Yahoo Pipes
Yahoo Pipes is an ingenious web app which provides a very intuitive GUI for remixing content without any complex syntax – you simply drag and drop the building blocks and then connect them together with pipes to control the flow and transformation of information. In one end you plug your data and out the other end comes a variety of feeds (RSS, JSON, email, mobile).
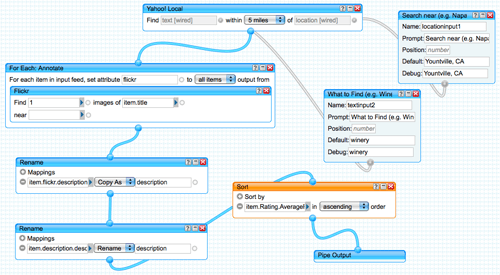
I’ve personally used Yahoo Pipes for a proof of concept at work and found it incredibly powerful yet simple to use. Whilst I would describe myself as technical, I’m not a hardcore developer and in that respect, this tool hits the nail on the head perfectly; I can visually plumb things together without having to write a line of code and know that it will be error-free. (More)
A cool enhancement to the RSS feeds Yahoo Pipes produces is to plug them into Feedburner so that you can take advantage of its enhancement, publishing and analysis tools.
Dapper
Dapper allows you to scrape websites using a visual interface, turning the data you select into dynamic web services (outputting to RSS, email, iCal, CSV, Google Gadgets and Google Maps). Dapper learns from the examples you feed it and then by comparison can create a query that turns an unstructured html page into a set of structured records. If the site you want data from doesn’t already provide a feed this is where you’ll want to go. (More)
OpenKapow
OpenKapow is more industrial strength than the other two; more powerful but more complex also. It uses a desktop-based visual IDE to gather data from websites which can then be processed by different types of “robots” to create RSS feeds, REST web services or Web Clips. Seems to be aimed more at professional developers rather than casual users but still a pretty cool tool if you need some serious power. (More)
More tools are examined here and here.
Whilst all these tools and technologies are very good there is still the issue of data cleanliness as we don’t have the same level of control or constraint that you get with relational databases. No doubt this will improve over time as the services mature but for those early adopters there’s still plenty to play with. Regardless of the labels we choose to give new concepts there is no doubt in my mind that this one is going to be big – watch this space!
Reply